
SQL vs NoSQL
The Difference That Still Confuses Many

I was talking about databases recently, and the question came up in a very simple way:
“What’s the real difference between SQL and NoSQL?”
At first, it sounds like an easy question.
But if you think about it, the answer isn’t that obvious.
A lot of explanations talk about speed, scale, or use cases. But they don’t really explain what’s fundamentally different underneath.
And that’s where the confusion usually stays.
Because the real difference isn’t just about performance.
It’s about how a system handles data, coordinates reads and writes, scales, and maintains correctness under load.
Once you see that clearly, everything else - consistency, performance, scaling - starts to fall into place.
Let’s look at it in a simple way.
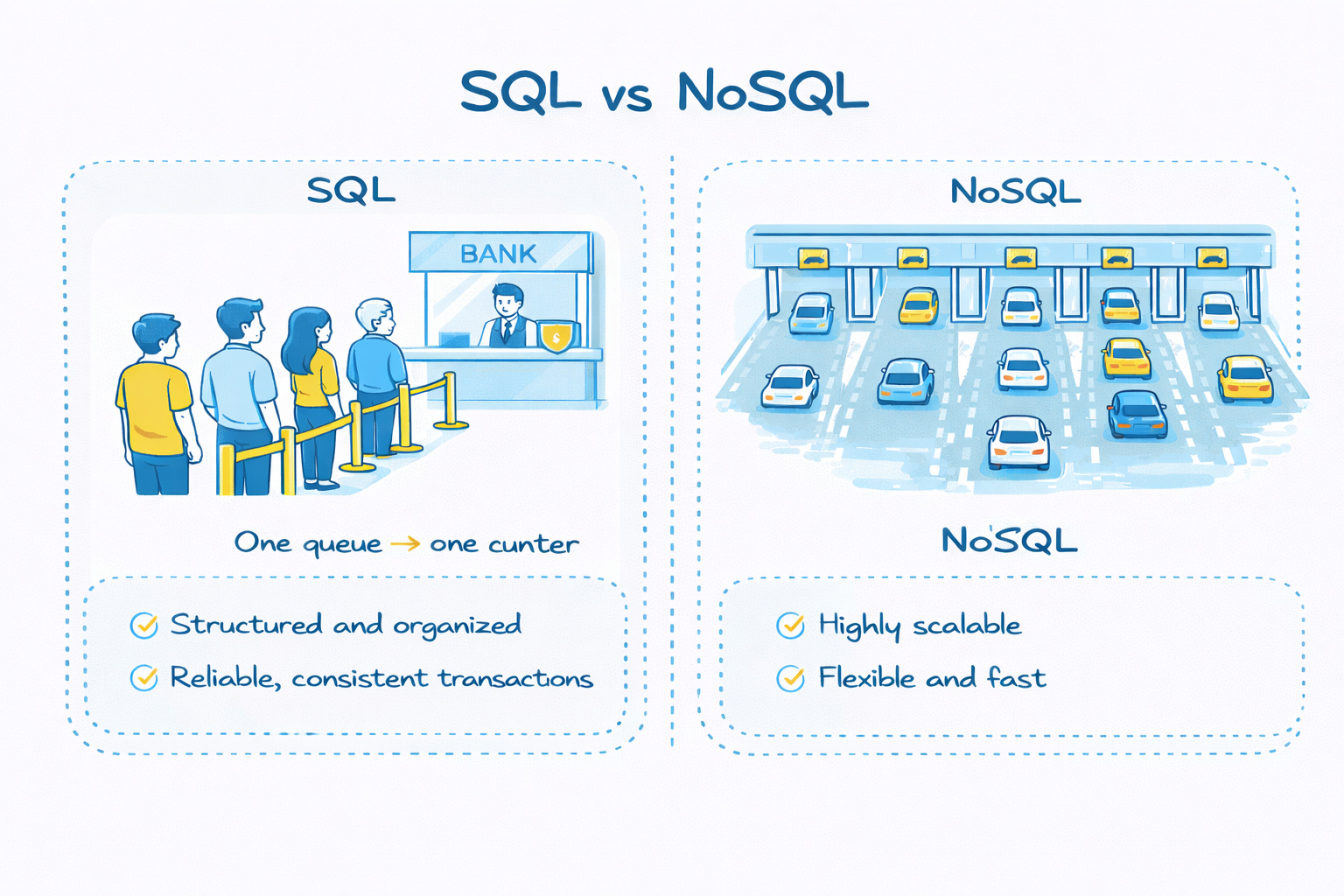
🔍A Simple Real-World Analogy
🏦 A Bank Cash Counter (SQL)
Imagine a bank with just one cashier handling all transactions.
Every transaction has to be right.
It must update the balance correctly
It must not be duplicated or lost
It must happen in the right order
Because even a small mistake here can turn into a much bigger problem later.
Now, when the queue grows, we don’t just open ten counters and let everyone update the same account freely… right?
Instead, the bank becomes more careful.
They add more checks.
They add more controls.
They improve the system.
They might upgrade the cashier’s machine.
They might make the process faster.
But they don’t compromise on correctness.
Speed matters, but only after correctness is guaranteed.
And even if you add more cashiers, they still need to coordinate before updating the same ledger. That coordination is the real bottleneck. - and it’s the price we pay for strong consistency.
In database terms, this is similar to ACID guarantees, where transactions are atomic, consistent, isolated, and durable.
That’s how many traditional SQL systems are designed.
🛣️ The Toll Plaza (NoSQL)
Now think of a busy highway toll plaza.
Cars don’t line up behind a single lane.
There are multiple lanes.
Each lane collects tolls independently.
Each lane keeps its own record.
In some cases, the system may reconcile data across lanes later.
If traffic increases, the solution is obvious : Add more lanes.or build another toll plaza.
Cars keep moving.
Throughput increases almost immediately.
This is similar to systems that prioritize availability and partition tolerance, sometimes accepting eventual consistency instead of immediate consistency.
This is how many NoSQL databases are designed.
🧩 Mapping It to the Software World
If we translate this directly
🔒 SQL feels like the bank
Writes go through a single, controlled path.
Transactions are ordered.
Consistency is non-negotiable.
You can make the system stronger with better hardware, better performance, and that’s how scaling usually happens.
You can distribute writes, but it’s not simple. It needs careful design and coordination.
SQL works best when data is structured and relationships matter.
⚡ NoSQL feels like the toll plaza.
Writes are distributed across nodes, often based on how data is partitioned.
Multiple nodes can accept writes at the same time.
Data is spread across the system.
Because of this, the system can scale very naturally. Schema is flexible too.
There’s a trade-off though - consistency rules can be a bit more relaxed or configurable, depending on what the system needs.
The focus here is simple, handle scale smoothly.
Now, this becomes even more interesting when you look at real workloads.
📊 Read-heavy vs Write-heavy workloads:
✍️ Write-heavy workload
In write-heavy systems,
SQL systems
start to feel pressure because many systems rely on coordination (often through a primary node or consensus mechanisms)
Scaling often involves sharding or partitioning, which is not trivial
NoSQL systems handle this more naturally:
Multiple nodes can accept writes
Load is distributed across partitionsRead-heavy workload
👀 Read-heavy workload
In read-heavy systems,
SQL does quite well with read replicas distributing the load (with possible trade-offs like replication lag)
NoSQL also scales reads easily because data is already distributed
So the real question isn’t just SQL vs NoSQL.
What kind of workload am I dealing with? and what consistency guarantees do I need?
⚖️ Trade-offs
SQL gives you strong guarantees.
Your data is consistent. Transactions are reliable. You can reason about the system easily.
But scaling writes becomes harder as the system grows, especially when strong consistency needs to be preserved.
NoSQL gives you flexibility and scale.
It handles large volumes of data and traffic smoothly. But you may need to think more carefully about consistency, data modeling, and access patterns.
Even replication reflects this difference.
SQL typically relies on a primary + replicas model, where writes go to one place (though newer distributed SQL systems exist)
NoSQL systems often allow writes across multiple nodes, making them more distributed by default
🧾 Ending Notes
At the core, the difference is actually very simple:
SQL systems typically require stronger coordination for writes, which makes horizontal scaling harder.
NoSQL systems relax or distribute that coordination, making horizontal scaling easier.
Everything else comes from this.
So the next time you’re designing a system, don’t start with:
Should I use SQL or NoSQL?
Start with:
How will my system handle reads and writes at scale, and what guarantees do I need?
Answer that honestly, and the right choice usually becomes clear.
💡 Liked this article? Subscribe to my newsletter for more insights on system design, software architecture, AI and practical tips from my experience - delivered straight to your inbox.